Design
Adaptive Incremental Checkpointing (AIC)
Adaptive incremental checkpointing (AIC) follows effective prediction on checkpoint overhead during execution progress to determine the desirable points of time to take checkpoints adaptively. AIC has been shown in our prior study to involve markedly smaller checkpoint files, when compared with prior checkpointing mechanisms which always take checkpoints at static time intervals or upon the occurrences of certain events (e.g., allocated time expiration, eviction due to resource unavailability, or job consolidation for energy reduction, etc.). It is especially valuable for Big Data analytics applications due to their often huge memory footprints.
AIC_DM: Adaptive Checkpointing in Support of CAR
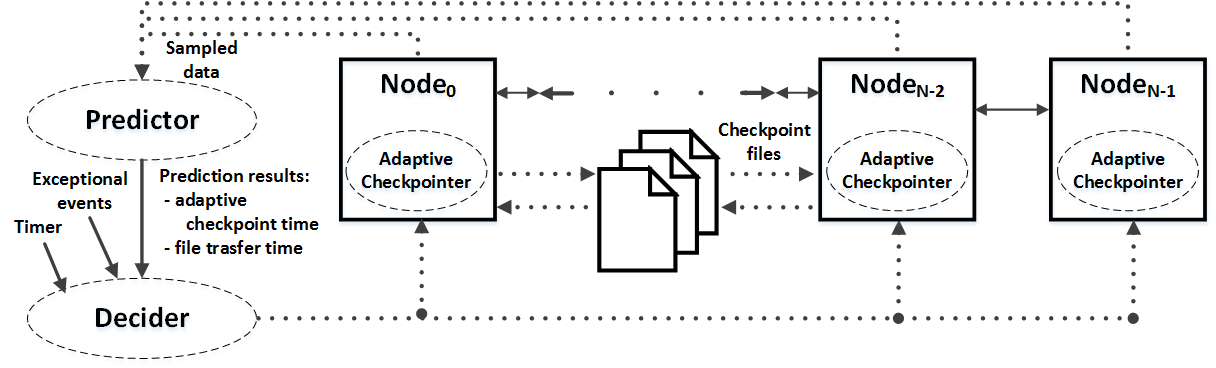
Adaptive checkpointing in support of CAR is among the major research activities under this project. Its schematic diagram is shown in the following figure, where a predictor is responsible for estimating "checkpoint time" and "file transfer time" according to sampled data gather from participating nodes. A decider is to issue "adaptive checkpoint instructions" to all nodes based on the predictor's results and other information, like a timer and exceptional events (to force checkpointing).
REX: Restore-Express Checkpointing
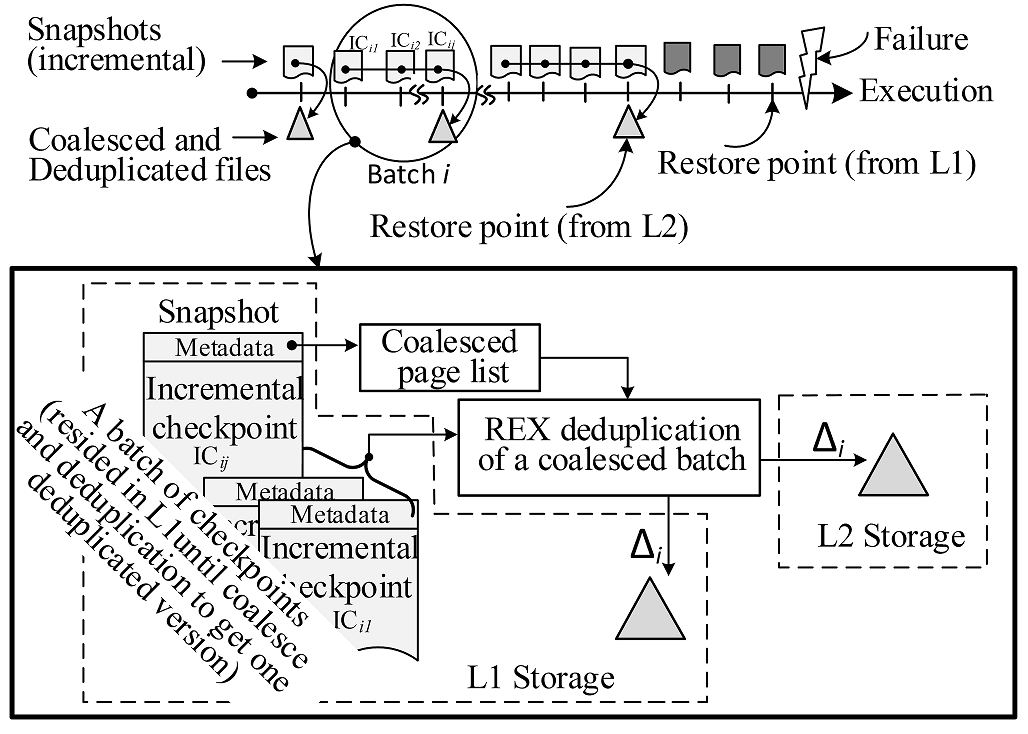
Execution state restore from failures is on the critical path, making it utterly important to shorten the restore time. To this end, our pursuit on restore-express (REX) checkpointing has its objectives of express restore from failures while holding down the overall execution time, with checkpoint files kept in both local nodes and remoted nodes as well for desired resilience. To lower checkpointing overhead, REX follows adaptive incremental checkpointing locally (L1), with an L2 checkpointing taken at the suitable time point after multiple L1 checkpoints, calling for varying L2 intercheckpoint intervals. REX achieves its objectives via exceeding overhead reduction as a result of (1) coalescing batches of IC files before checkpointing them in L2 storage and (2) deduplicating data patterns both within each L2 checkpoint and across multiple L2 checkpoints, accelerating restore from failures.
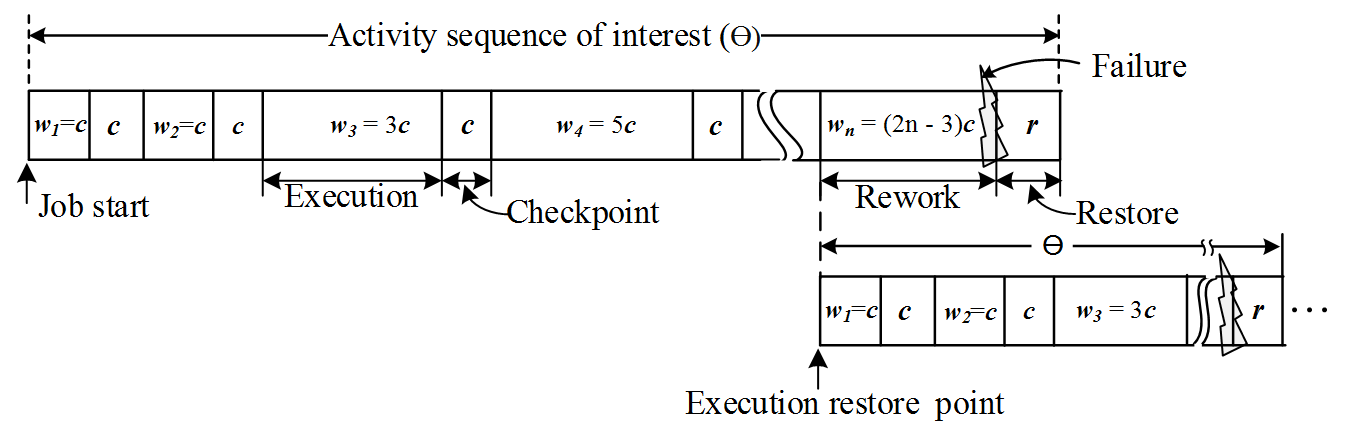
CHORE: Checkpointing Overhead and Rework Equated
In light of real-world computing systems to have either unknown failure rates a priori or widely varying MTBFs, we have attempted for the first time, efficient checkpointing control with the objectives of (1) being olivious to system's failure rates and (2) bounding execution time overhead, with respect to the lowest time overhead achievable by optimal checkpointing in an ideal system with known and fixed MTBF. Our analyses on the mean time over two consecutive checkpoints are undertaken to identify one that minimizes normalized execution time overhead, under following practical assumptions: (1) failures possible to happen randomly during job execution and also during checkpointing and restoration, (2) all restoration and rework costs taken into consideration. The proposed checkpointing control results from analyzing an activity sequence of interest (called ϴ) which starts from execution onset or resumption (from the previous failure) until execution state recovery from the following failure (if it occurs), to determine suitable inter-checkpointing intervals over ϴ that targets performance optimality.