Results
REX: Restore-Express Checkpointing
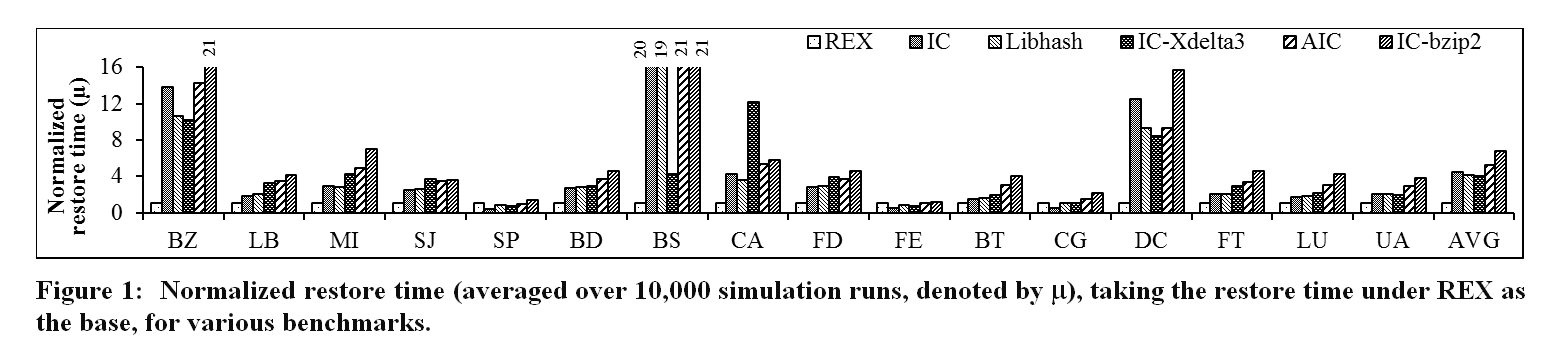
REX has been implemented and evaluated extensively on a multi-core testbed, which consists of four Dell PowerEdge R610 servers, each with two quadcore Xeon E5530 processors that operate at 2.4 GHz and have 8-MB shared cache each, using three benchmark suites, including SPEC CPU2006, PARSEC, and NAS Parallel Benchmarks (NPB 3.3.1). Evaluation outcomes of the execution restore time confirm that REX is fast and able to quicken restore by a factor of 4.5 when compared with its IC counterpart (without utilizing the unique insights), while incurring same execution time overhead.
CHORE: Checkpointing Overhead and Rework Equated
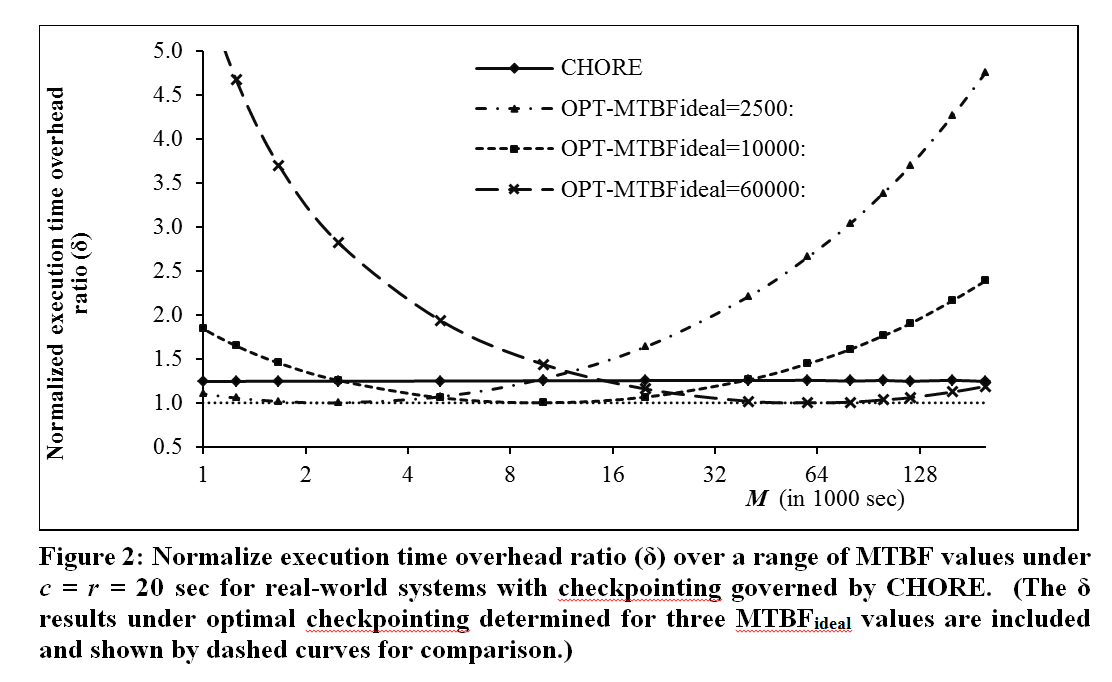
CHORE is shown analytically to keep overall execution time overhead upper bounded by 1.25x of time overhead incurred under optimal checkpointing with a fixed inter-checkpointing interval in an ideal counterpart system. Intrinsically, such a time overhead upper bound holds for wide ranges of MTBFs, checkpoint costs, and restore costs, whereas optimal checkpointing with a constant inter-checkpoint interval can exhibit arbitrarily large execution time overhead. Extensive simulation evaluation on CHORE performance have been conducted, with its outcomes confirming the time overhead upper bound of CHORE. If an ideal system with constant MTBF (say, MTBF_ideal) incurs 4% execution time overhead following its optimal inter-checkpointing interval, CHORE leads to approximately 5% execution time overhead. In general, CHORE is to yield shorter total execution times on a real-world system than what are achievable under optimal checkpointing determined by constant MTBF_ideal, if the system's MTBF is deviated from MTBF_ideal by a factor of 4 or more.
Collaborative Effort
The PI and his team had adopted BigDataBench codes with CED (concurrent error detection) and periodical execution state checkpointing (via Berkeley Labs Checkpoint Restart, BLCR) incorporated, for experimental evaluation. Some preliminary evaluation results were obtained for five BigBench applications. It has been discovered that applications which suffer from silent data corruption commonly (like Quicksort) are to benefit from CED markedly with considerable fault coverage hikes, while increasing the execution time slightly. On the other hand, applications with a lot of pointer arithmetic and dereferencing (such as matrix multiplications) appear to experience frequent program abortion, rendering CED to be of little benefit to fault coverage improvement. In addition, collaborative effort has been engaged in the log-based detection system by identifying individual instructions or memory locations and enforcing concurrency constraints on them through Intel Pin. When errors are detected, the system is rolled back attempting to correct those errors. There are two main structures for parallel thread control of our focus: locks and barriers. To use locks for example, all memory accesses within the critical section are "owned" by a thread and released when complete; multiple owners for a location signal a lock failure. Barriers by comparison mark the barrier location and are enforced through Pin. We are to perform experiments on a workstation jointly by the two research teams. The results will be submitted to an upcoming conference.

